새롭게 푼 문제는 블로그에 꼬박꼬박 올리려 하고 있으나,
제가 블로그를 좀 늦게 시작했다 보니,
기존에 푼 문제는 포스팅하지 않아, 최근에 기존에 푼 문제도 하나씩 포스팅을 하고 있습니다.
그런데, 맞은 문제들 중에서 포스팅하지 않은 문제를 찾으려니,
백준 문제 제목 복사 - 블로그에서 검색 - 없으면 포스팅, 있으면 처음으로 이동
위 작업을 하나씩 하려다 보니 너무 귀찮은 겁니다...ㅠ
그래서 백준에 있는 문제 리스트와 블로그에 포스팅한 문제 리스트를 갖고와
서로 비교한 후, 백준에서 푼 문제 중 블로그에 포스팅하지 않은 문제만 필터링하고자, IDE를 키고 코드를 적어나갔습니다.
크롤링(Crawing)?
크롤링(Crawing), 혹은 스크래핑(Scraping)은 웹 페이지의 내용을 가져와
원하는 내용을 추출하는 작업을 의미합니다.
크롤링과 스크래핑, 두 기술은 웹의 정보를 가져온다는 점에서 서로 비슷하지만, 약간의 차이가 있습니다.
다만, 본 포스팅은 크롤링과 스크래핑의 차이를 논하는 것이 목적은 아니므로, 넘어가도록 하겠습니다.
크롤링으로 주로 사용되는 언어는 파이썬이지만,
저는 코틀린이 편하니, 코틀린을 사용해 크롤링을 해보겠습니다.
자바와 문법이 약간 다를 뿐, 본 포스팅에서 사용하는 메소드와 라이브러리, 자료구조는 모두 자바 기반이기 때문에
자바에서 크롤링 하는 것은 얼마든지 가능합니다.
Jsoup 준비
Jsoup 다운로드
자바 / 코틀린에서 크롤링을 하기 위해선 Jsoup라는 라이브러리가 필요합니다.
Download and install jsoup
Download and install jsoup jsoup is available as a downloadable .jar java library. The current release version is 1.15.3. What's new See the 1.15.3 release announcement for the latest changes, or the changelog for the full history. Previous releases of jso
jsoup.org
위 링크를 통해 다운로드 받아 주세요.
Intellij에서 Dependencies 추가

intellij로 와서 File - Project Structure - Modules 에서 +버튼을 눌러 다운로드 받은 .jar 파일을 추가시킵니다.
크롤링을 위한 준비는 끝났으니, 크롤링을 시작해봅시다.
백준에서 푼 문제 가져오기
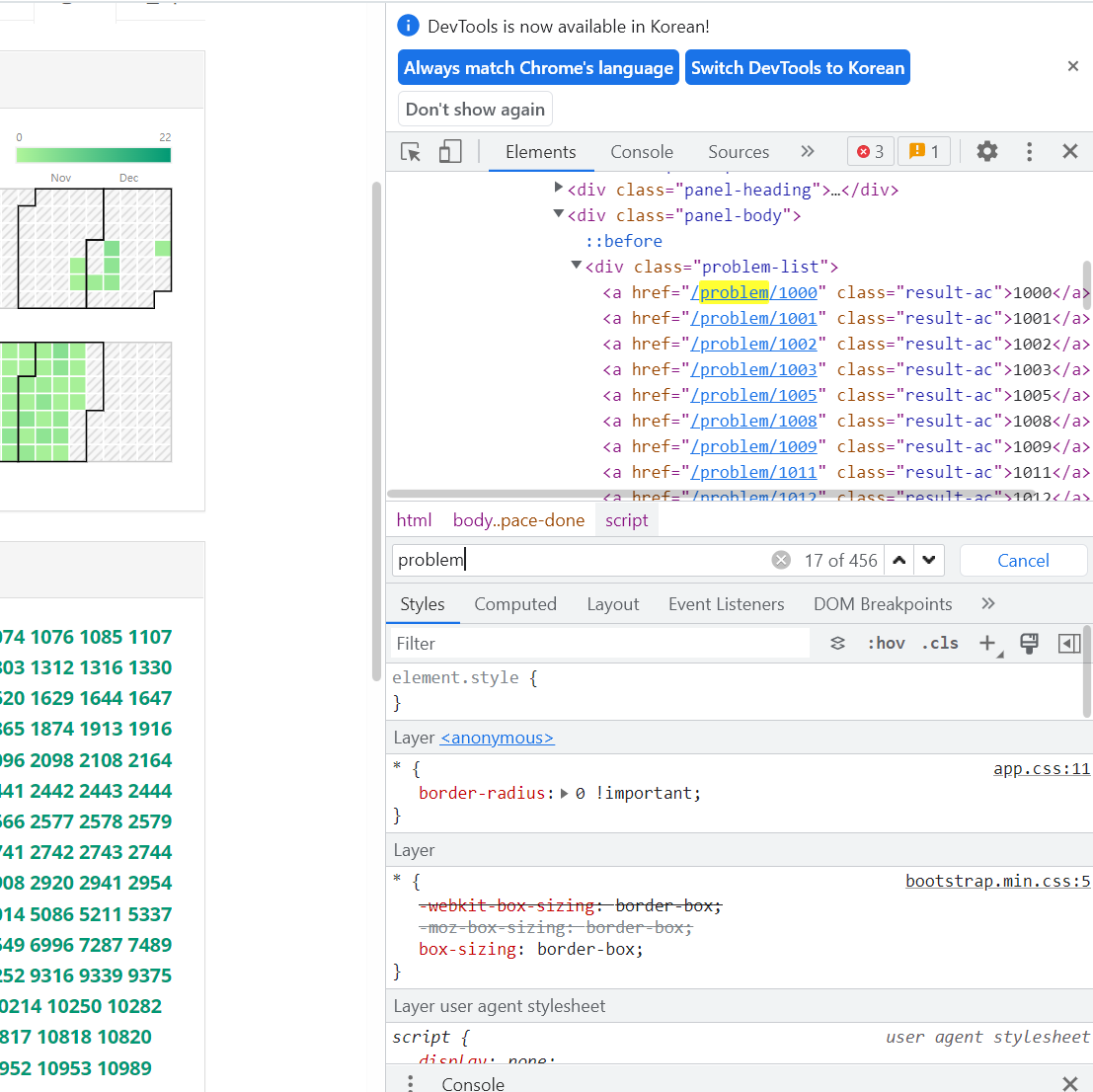
백준 마이페이지에서 개발자 모드(F12)를 키고,
맞은 문제 구역을 살펴보니 problem-list 라는 클래스가 있네요. 이 부분을 긁어오면 될 것 같습니다
val url = "https://www.acmicpc.net/user/yoon6763"
val conn = Jsoup.connect(url)
val html = conn.get()
// 맞은 문제, 시도했지만 맞지 못한 문제, 맞은 번외 문제
val classTag = html.getElementsByClass("problem-list")
val problemsTags = classTag[0].getElementsByTag("a")
val bjProblems = problemsTags.map { it.text().toInt() }
getElementsByClass를 사용해 클래스 이름으로 원소를 찾을 수 있습니다.
해당 페이지에서는 맞은 문제, 시도했지만 풀지 못한 문제, 맞은 번외 문제 3개의 "problem-list" 클래스가 있어,
그중 첫번째 원소를 갖고 왔습니다.
<a href="/problem/1000" class="result-ac">1000</a>
그러면 이와 같이 값을 가져 올 텐데요.
text 값인 1000을 가져오고 싶다면 ().getElementsByTag("a").text()를 통해 1000 부분을 가져올 수 있습니다
저는 이걸 map을 사용해 각 원소를 int 형태로 변환해줬습니다
포스팅한 문제 가져오기
val blogProblems = ArrayList<Int>()
for (i in 1..100) {
try {
println("티스토리 탐색 - $i")
val tistoryUrl = "https://uknowblog.tistory.com/$i"
val tistoryConn = Jsoup.connect(tistoryUrl)
val tistoryHtml = tistoryConn.get()
val title = tistoryHtml.title()
if (title.startsWith("[백준 ")) {
val problem = title.split("]")[0].filter { it.isDigit() }.toInt()
blogProblems.add(problem)
}
} catch (e: Exception) {
println("오류페이지 => $i")
}
}
println("\n\n포스팅하지 않은 문제")
알고리즘 문제만을 어떻게 가져올까... 생각하다가
크롤링이 익숙하지 않아 일단 뒤의 페이지 idx만 바꾸고, 모든 페이지를 방문하면서
타이틀이 "[백준 "으로 시작하는 페이지만 갖고오고,
"]" 기준으로 split해 숫자만 가져왔습니다.
페이지의 타이틀은 html.title()을 사용해 가져올 수 있습니다.
포스팅한 문제인지 비교
bjProblems.forEach {
if (it !in blogProblems) {
println(it)
}
}
println("총 풀은 문제 : ${bjProblems.size}\t총 포스팅한 문제 : ${blogProblems.size}\t포스팅하지 않은 문제 : ${bjProblems.size - blogProblems.size}")
데이터가 몇만개씩 있는게 아니다보니,
간단하게 백문의 푼 문제를 돌며 !in 연산을 통해 포스팅한 리스트 안에 있는지를 구했습니다

아직 포스팅하지 않은 문제가 356 문제나 있군요... 허허.....
'언어 > Kotlin' 카테고리의 다른 글
| 코틀린의 반올림 방식 : 오사오입 (0) | 2023.06.14 |
|---|---|
| [Kotlin/코틀린] 여러 조건을 기준으로 정렬하기 (0) | 2023.05.21 |
| 자바의 StringBuilder 개행문자 삽입방법 - append(str + "\n") vs append(str).append("\n") (0) | 2023.02.01 |
| [Kotlin] BigDecimal을 사용하여 매우 큰 수, 소숫점 처리하기 (0) | 2022.12.21 |
| [Kotlin] 배열 사용법 정리 (1) | 2022.02.16 |