1. 코틀린으로 백준 풀기
1일 1코딩테스트를 한 지도 500일이 넘었네요.
아직 보잘 것 없는 실력이긴 하나, 그동안 백준을 풀며 얻은 팁들을 끄적여볼까 합니다.
2. main() 함수의 매개변수는 생략 가능
<kotlin />
fun main(args: Array<String>) {
}
// main 함수 매개 변수는 생략 가능
fun main() {
}
자바를 주로 써왔기에 public static void main(String[] args)과 같이 main 함수에 매개변수를 넣는게 익숙했고,
코틀린에서 클래스를 생성했을 때, main() 함수 내 args: Array<String>이라는 매개변수를 자동으로 만들어주길래,
당연히 넣어줘야 하는 줄 알았으나... 사실 생략이 가능합니다.
3. readln(), readLine()으로 입력받기
<kotlin />
fun main() {
// readln(), readLine()
val input = readln()
val inputNullable = readLine()
// Scanner
val sc = Scanner(System.`in`)
val input2 = sc.nextInt()
}
자바와 달리 Scanner 클래스를 인스턴스화하여 입력을 받지 않고,
readln()과 readLine()을 사용하여 입력을 받을 수 있습니다.
readln()과 readLine()의 차이는 null의 허용가능 유무로써,
realn()은 null을 허용하지 않는 입력을, readLine()은 null을 허용하는 입력입니다.
알고리즘을 풀 때에는 아직까진 null을 허용하는 입력을 받아볼 일이 없어 readln()을 주로 사용합니다.
처음 코틀린으로 백준을 풀 당시에는 readln()이 없어 readLine()에 !!를 붙여 사용하곤 했는데,
readln()이 생긴 뒤로는 간편히 readln()을 사용하고 있습니다.
4. BufferedReader 사용하기
4.1. 인스턴스화 방법
<kotlin />
fun main() {
val br = BufferedReader(InputStreamReader(System.`in`))
val br = System.`in`.bufferedReader()
}
자바로 백준을 풀다가 입출력만으로도 시간초과가 발생한 경험이 있으신 분들은
Scanner 보다는 BufferedReader가 더 빠르다는 것을 아실겁니다.
이는 코틀린에서도 마찬가지로, readln()과 readLine() 보다는 BufferedReader가 더 빠릅니다.
코틀린에서는 BufferedReader(InputStreamReader(System.in) 대신
System.`in`.bufferedReader()와 같이 쉽게 인스턴스화가 가능합니다.
(물론 전자의 방법도 가능합니다.)
코틀린에서는 BufferedReader를 사용하여도
IOException이나 try-catch 등을 사용하지 않아도 됩니다.
4.2. with와 함께 써보기
<kotlin />
fun main() = with(System.`in`.bufferedReader()) {
val n = readLine().toInt()
}
with는 코틀린에서 사용되는 스코프(Scope) 함수 중 하나로,
with()로 감싸준 객체 내 컨텍스트 안에서 코드를 실행하게 해줍니다.
간단히 말해, 객체의 이름을 언급하지 않아도 된다고 말할 수 있는데요.
br.readLine의 앞에 br을 생략하여도, BufferedReader의 readLine()을 호출할 수 있습니다.
(이 경우, 메소드 명이 같은 기존 Console 클래스의 readLine() 메서드보다 우선시되어 사용됩니다.)
https://uknowblog.tistory.com/240
[코파기 3부] 4. 코틀린과 스코프 함수 : apply, run, with, also, let
스코프 함수 (Scope Function) 스코프 함수(Scope Function)란, 객체의 컨텍스트 내에서 코드 블록을 실행하는 것이 유일한 목적인 여러 함수들 입니다. 개체에서 스코프 함수를 호출하면 람다식으로 임
uknowblog.tistory.com
5. split(" ")으로 분리 후, map으로 Int로 바꿔주기
<kotlin />
fun main() {
val arr = readln().split(" ").map { it.toInt() }
println(arr)
}
// 입력
234 4 5 67 8
// 출력
[234, 4, 5, 67, 8]
split은 특정 문자를 기준으로 문자열을 나누는 메서드입니다.
map은 주어진 컬렉션(배열, 리스트 등)의 각 요소에 대해 특정 연산을 수행하고,
그 결과를 새로운 컬렉션으로 반환하는 메서드입니다.
위 코드에서 map { it.toInt() } 은 split(" ")으로 분리된 각각의 원소(String)에 접근하여
toInt()로 Int 형으로 만든 뒤, Int형 List를 반환하는 역할을 합니다.
해당 포스팅에서는 String을 Int형으로 변환하는데에 사용하는 것만 설명하고 있지만,
익숙해진다면 꽤나 다양한 용도로 사용할 수 있습니다.
6. Array(n) { readln() }
<kotlin />
fun main() {
val arr = Array(9) { it }
println(arr.contentToString())
val arr2 = Array(9) { it * 2 }
println(arr2.contentToString())
val arr3 = Array(9) { it / 2 }
println(arr3.contentToString())
val arr4 = Array(9) { it + 3 }
println(arr4.contentToString())
val arr5 = Array(9) { 3 } // 꼭 it을 사용하지 않아도 됨
println(arr5.contentToString())
}
// 출력
[0, 1, 2, 3, 4, 5, 6, 7, 8]
[0, 2, 4, 6, 8, 10, 12, 14, 16]
[0, 0, 1, 1, 2, 2, 3, 3, 4]
[3, 4, 5, 6, 7, 8, 9, 10, 11]
[3, 3, 3, 3, 3, 3, 3, 3, 3]
코틀린은 람다식을 사용해 배열의 선언과 생성부터 값 초기화를 한 줄에 끝낼 수도 있습니다.
자바를 주로 써왔기에 다소 어색하였으나, 익숙해지면 꽤나 편리합니다.
여기서 it은 현재 처리 중인 요소를 가르키는 키워드로써
iterator 혹은 it(대명사)의 중의적인 의미가 아닐까 싶은데요.
배열의 생성단계의 중괄호 내에서 사용되는 it은 index 값을 의미합니다.
하지만, { } 안의 로직은 지정한 배열 내 사이즈 횟수만큼 실행된다는 점과,
{ } 안의 로직의 결과값이 배열 내 원소가 된다는 점을 이용한다면 아래와 같이 사용할 수도 있습니다.
<kotlin />
fun main() {
val n = readln().toInt()
val arr = Array(n) { readln() }
println(arr.contentToString())
}
/*
첫 줄에 원소의 개수 n이 주어진 후,
그 다음 n개의 줄에 걸쳐 각 원소의 값이 주어진다.
*/
// 입력
5
345
34
1245
3
0
// 출력
[345, 34, 1245, 3, 0]
백준에서는 첫 번째 줄에 원소의 개수 n이 주어진 후,
그 다음 n개의 줄에 각 원소의 값이 주어지는 유형의 문제가 흔히 있는데,
이 경우 위와 같이 readln()을 중괄호 내에 넣어주면
배열의 선언과 생성, 초기화(입력)까지 한 줄에 끝낼 수가 있습니다.
7. Destructuring (객체/배열/리스트 분해)
<kotlin />
fun main() {
val intArray = arrayOf(1, 3, 4)
val (a, b, c) = intArray // Destructuring
println("$a $b $c")
}
// 출력
1 3 4
코틀린에서는 객체 분해 / 객체 비구조화(Destructuring)을 지원하여
객체 내 필드 혹은 리스트, 배열의 원소를 각각의 변수에 할당할 수 있습니다.
위 예시에서는 1, 2, 3을 원소로 가지고 있는 int형 배열을
a, b, c 세 변수로 분해하는 과정을 나타내었습니다.
<kotlin />
// 기존 방법
val nm:List<Int> = readln().split(" ").map { it.toInt() }
val n = nm[0]
val m = nm[1]
// Destructuring을 사용한 방법
val (n, m) = readln().split(" ").map { it.toInt() }
// 입력 예시
3 4
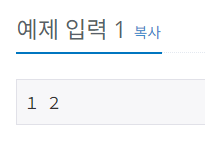
백준에서는 위와 같이 공백을 기준으로 분리된 두 숫자가 주어지는 유형은 꽤나 흔합니다.
저는 자바를 사용할 때에는 입력을 받은 뒤, split(" ")으로 분리하여 nm 리스트(혹은 배열)에 임시 저장한 뒤,
n, m에 할당하는 방법을 주로 쓰곤 했습니다.
하지만 비구조화를 사용한다면 꽤 간편하게 n, m을 입력받을 수 있습니다.
파이썬에서 부러웠던 기능이였는데 코틀린에서 만나니 정말 반갑군요.
관련 문제 : https://www.acmicpc.net/problem/1000
1000번: A+B
두 정수 A와 B를 입력받은 다음, A+B를 출력하는 프로그램을 작성하시오.
www.acmicpc.net
풀이 코드
<kotlin />
fun main() {
val (a, b) = readln().split(" ").map{ it.toInt() }
println(a+b)
}
8. StringTokenizer 사용하기
자바로 알고리즘을 하셨던 분들이라면 익숙할 수 있는, StringTokenizer 입니다.
코틀린에서도 여전히 자주 만나는 친구 중 하나입니다.
<kotlin />
입력 : 1 2 3 4 5 6 7 8 9 10
fun main() {
val arr = readln().split(" ").map {it.toInt() } // 느릴 수 있음
}
위와 같이, readln() 혹은 BufferedReader의 readLine()을 사용하여 split(" ")으로 나누고,
map으로 각각 int로 바꿔줬더니 시간초과를 경험한 적이 종종 있었습니다.
<kotlin />
val st = StringTokenizer(readln(), " ")
// 구분자가 공백일 경우 생략 가능
// val st = StringTokenizer(readln())
while (st.hasMoreTokens()) {
println(st.nextToken().toInt())
}
// 입력
1 2 3 4 5 6 7
// 출력
1 2 3 4 5 6 7
StringTokenizer를 사용하면 문자열을 특정 문자 기준으로 더 빠르게 쪼갤 수 있습니다.
구분자가 공백 (" ")일 경우 생략 가능합니다.
hasMoreTokens()는 StringTokenizer안에 원소가 남아있는지를 반환하는 메서드이며,
nextToken()을 사용해 다음 원소를 뽑아옵니다.
단, String 형태이므로, Int 형 원소를 입력받았다면 toInt()로 Int형으로 변환하는 과정이 필요합니다.
9. Array(n) { st.nextToken() }
앞서 Array(n) { readln() }의 StringTokenizer 버전으로 응용이 가능합니다.
<kotlin />
fun main() {
val st = StringTokenizer(readln())
val n = st.nextToken().toInt()
val arr = Array(n) { st.nextToken().toInt() }
println(arr.contentToString())
}
/*
첫 번째로 n이 주어진 후, 그 다음 n개의 원소가 주어진다.
*/
// 입력
// 5 1 523 23 21 5
// 출력
[1, 523, 23, 21, 5]
한 줄에 첫 번째로 원소의 길이가 주어진 뒤, 그 뒤에 n개의 정수가 입력으로 주어지는 경우가 있습니다.
이 경우에 꽤 유용하게 사용이 가능합니다.
10. 특정 횟수 만큼 반복하는게 목적일 때는 repeat
<kotlin />
fun main() {
val T = readln().toInt()
repeat(T) {
println(it)
}
}
// 입력
5
// 출력
0
1
2
3
4
종종 한 테스트케이스 자체적으로 여러 테스트 케이스로 나뉘어 있는 경우가 있습니다.
이와 같이 단순 반복을 목적으로 하는 경우엔 repeat 반복문이 유용하게 쓰일 수 있습니다.
repeat 블록 내 it 키워드는 index의 값이 담깁니다.
단, 특정 횟수만큼 반복하면서
반복문의 흐름을 제어(break, continue 등)하는게 목적이라면 for문을 사용하는 것이 좋습니다.
repeat 반복문의 목적은 '특정 횟수만큼 단순히 반복'하는 것이기 때문입니다.
11. StringBuilder
자바 개발자에게는 역시나 친숙한 이름입니다.
println() / System.out.println()은 출력하는데 시간이 다소 소요될 수 있습니다.
때문에 출력할 일이 생길 때 마다 출력하는 것 보다는,
문자열을 합쳐준 뒤 한꺼번에 출력하는 것이 더 효율적일 수 있습니다.
<kotlin />
fun main() {
var result = ""
result += "Hello World!\n"
result += "Good Bye!"
println(result)
}
// 출력
Hello World!
GOod Bye!
하지만 문자열을 합치기 위해
위와 같이 String 변수에 계속 문자열을 이어주는 것은 그리 바람직하지 않습니다.
단순히 String 변수 마지막 부분에 새 문자열이 이어 붙여지는 것이 아닌,
합치려는 두 String 변수 내부의 값을 각각 복사한 뒤,
이를 합친 새로운 String 객체를 생성해 반환하는 과정으로 이루어지기 때문입니다.
<kotlin />
fun main() {
val sb = StringBuilder()
sb.append("Hello World!").append("\n")
sb.append("Good Bye!").append("\n")
print(sb)
}
// 출력
Hello World!
Good Bye!
때문에 문자열 뒤에 새 문자열을 이어붙이는 작업을 할 때에는
StringBuilder를 사용하는 것이 좋습니다.
<kotlin />
sb.append(name + "\n") // 얘 보다는
sb.append(name).append("\n") // 얘가 더 빠름
참고로 StringBuilder에서 개행문자를 추가할 경우,
전자와 같이 String 변수 + "\n"과 같이 사용할 경우,
두 String 변수의 값이 각각 복사된 후, 두 변수의 값을 합친 새 변수를 생성해 StringBuilder에 넘겨주기 때문에
아래와 같이 사용하는 것이 더 효율적입니다.
이와 관련한 더 자세한 내용은 이 글을 참고해주세요.
<kotlin />sb.appendLine(name)
\n을 마지막에 추가하는 것이 귀찮다면, appendLine 메소드를 사용하면 됩니다.
appendLine은 마지막에 자동으로 개행문자를 추가해줍니다.
저도 최근에 알게된 메소드입니다....
12. 숏 코딩 / 한줄 코딩
1일 1코딩테스트를 이어나가야 하는데,
해야할 일이 너무 많을 때엔 종종 브론즈 문제를 풀곤 합니다.
그냥 풀면 재미없기에 숏 코딩 / 한 줄로 짜기를 해보곤 하는데,
이에 대한 내용도 조금 적어볼까 합니다.
!! 아래 내용은 어디까지나 재미로 봐주세요 !!
https://www.acmicpc.net/problem/1181
1181번: 단어 정렬
첫째 줄에 단어의 개수 N이 주어진다. (1 ≤ N ≤ 20,000) 둘째 줄부터 N개의 줄에 걸쳐 알파벳 소문자로 이루어진 단어가 한 줄에 하나씩 주어진다. 주어지는 문자열의 길이는 50을 넘지 않는다.
www.acmicpc.net
백준 1181번 단어 정렬을 예시로 가져와봤습니다.
1. 길이가 짧은 순 부터 정렬
2. 길이가 같으면 사전 순으로 정렬
3. 중복 문자 제거
4. 결과 출력
총 네 단계로 나눌 수 있는데요.
<kotlin />
fun main() {
val n = readln().toInt()
var arr = Array(n) { readln() } // 선언+생성과 동시에 초기화(입력받기)
arr = arr.distinct().toTypedArray() // 중복 제거
arr.sortWith(compareBy({ it.length }, { it })) // 다중 조건 정렬
// repeat을 사용해 n번 반복
repeat(n) {
println(arr[it])
}
}
위와 같이 Array(n) { readln() } 형태로 선언 + 생성 + 초기화(입력받기)를 해주었고,
distinct()를 사용해 중복을 제거해줬습니다.
sortWith를 사용해 다중 조건 기준으로 정렬을 해주었고, (자세히 알고 싶으신 분은 이 링크를 클릭)
repeat()으로 n번 만큼 반복해줬습니다.
<code />
fun main() {
val n = readln().toInt()
var arr = Array(n) { readln() }
arr = arr.distinct().toTypedArray()
arr.sortWith(compareBy({ it.length }, { it }))
arr.forEach { println(it) }
}
여기서 repeat 대신 forEach를 사용해보겠습니다.
forEach는 리스트/배열 내 원소를 순회하는 함수로써, 여기서의 it은 각각의 원소의 값이 담깁니다.
println(it)으로 각 원소의 값(it)을 출력합니다.
<code />
fun main() {
val n = readln().toInt()
var arr = Array(n) { readln() }
arr = arr.distinct().toTypedArray()
arr.sortWith(compareBy({ it.length }, { it }))
arr.forEach(::println)
}
또, forEach의 body가 한 줄일 경우, 위와 같이 :: 형태로 축약할 수도 있습니다.
forEach를 사용하여 n을 사용하는 곳이 한 곳으로 줄었기 때문에 n을 굳이 변수로 받지 않아도 됩니다.
<code />
fun main() {
var arr = Array(readln().toInt()) { readln() }
arr = arr.distinct().toTypedArray()
arr.sortWith(compareBy({ it.length }, { it }))
arr.forEach(::println)
}
n을 굳이 변수로 받지 않고 Array()의 배열의 크기를 명시하는 곳에 바로 넣어줬습니다.
또, sortWith는 원본 리스트를 변경하나,
sortedWith를 사용하면 정렬된 리스트를 반환합니다.
때문에 distinct()와 정렬작업까지 굳이 줄을 나누지 않아도 됩니다.
<code />
fun main() {
var arr = Array(readln().toInt()) { readln() }.distinct().sortedWith(compareBy({ it.length }, { it })).forEach(::println)
}
원본이 바뀌는 sortWith 대신, 바뀐 리스트를 반환하는 sortedWith를 사용하여,
Array(readln().toInt()) { readln() } 으로 만든 배열의 중복 제거, 정렬, 출력까지 한 줄에 하였습니다.
이제 var arr로 변수로 따로 받을 필요가 없으니 이 부분도 지워줍니다.
<code />
fun main() {
Array(readln().toInt()) { readln() }.distinct().sortedWith(compareBy({ it.length }, { it })).forEach(::println)
}
여기서 코틀린의 한 가지 특성이 또 쓰일 수 있습니다.
바로 함수의 바디가 한 줄이면 중괄호 { } 도 생략이 가능하다는 점인데요...!
<code />
fun main() = Array(readln().toInt()) { readln() }.distinct().sortedWith(compareBy({ it.length }, { it })).forEach(::println)
함수의 바디가 한 줄이면 { } 를 생략하고 =와 같이 사용할 수 있습니다.
한 줄 코딩이 완성되었습니다!
숏코딩은 어디까지나 재미로, 취미로만 하고 있고
숏코딩/한줄 코딩 파트 부분은 절대 진지하게 포스팅한 점이 아니란 점 다시 알려드립니다! 😅
13. 마치며
코틀린을 사용한지도 어느덧 2년이 지난 것 같습니다.
그동안 써본 소감을 한 줄로 표현하자면... mz스러워진 자바? 라고 해야 할까요.
자바와 파이썬을 합친 듯한 느낌을 받았어요.
자바를 정말 대체할 목적으로 만든 느낌을 받은 언어인데요.
자바가 주 언어일 때에는 딱히 불편한 느낌을 받지 못하였는데,
코틀린을 쓰고난 뒤 자바를 다시 쓰려니까 불편한 점을 꽤나 느낍니다. 🤣
정말 자바를 대체할 목적으로 만들었구나 싶었습니다.
아직 형편없는 실력이지만, 그동안 코딩테스트를 하며 얻은 노하우들을 적어봤습니다.
부디 도움이 되었으면 좋겠네요. 다들 즐거운 코딩테스트 하기 바랍니다!

'코딩테스트 > Kotlin' 카테고리의 다른 글
| [백준 3184번] [Kotlin] 양 (1) | 2023.12.30 |
|---|---|
| [백준 21610번] [Kotlin] 마법사 상어와 비바라기 (1) | 2023.12.27 |
| [백준 16562번] [Kotlin] 친구비 (1) | 2023.12.18 |
| [백준 11559번] [Kotlin] Puyo Puyo (0) | 2023.12.17 |
| [백준 17141번] [Kotlin] 연구소 2 (0) | 2023.12.15 |